



인공지능, 딥러닝, 머신러닝은 혼용되고 있지만, 엄연히 다릅니다. 구조적으로는 인공지능이라는 가장 큰 개념에 머신러닝이 포함되어 있고, 머신러닝이라는 상위 개념에 딥러닝이 포함되어 있습니다.
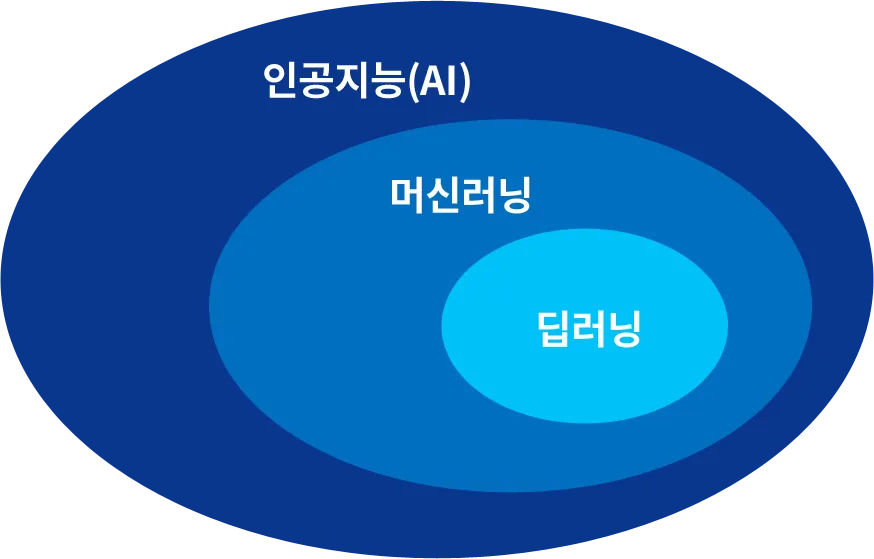
머신러닝은 컴퓨터가 데이터 속에서 다양한 것들을 학습하고 예측할 수 있도록 하는 인공지능의 한 형태라고 할 수 있습니다.
이 머신러닝의 알고리즘은 일반적으로 데이터를 통해 훈련되고 이러한 훈련이 반복되며 정확도가 올라갑니다. 머신러닝은 간단하게는 텍스트 분류나 요약부터 추천 시스템, 주식 시장 예측 등 많은 곳에서 활용되고 있습니다.
기존의 인공지능 같은 경우, 규칙과 데이터를 입력하면 정답을 도출하는 형태였습니다.
예를 들어, '발이 네 개다,' '털이 있다.' '꼬리가 달렸다.' '귀엽다.'라는 규칙을 주고 강아지 사진을 입력하면 '강아지'라는 답을 도출하는 것이 인공지능입니다.
하지만 이 규칙들은 고양이에게도 해당하는 규칙들이기 때문에, 같은 규칙을 주고 고양이 사진을 입력해도 '강아지'라는 잘못된 답을 도출하게 된다는 문제점이 있었습니다.
하지만 머신러닝은 데이터와 정답을 입력하면 스스로 그 안의 규칙을 찾아내어 정답을 도출한다는 점이 새롭습니다.
머신러닝이라는 학문은 기계가 명시적으로 코딩되지 않은 동작을 스스로 학습해 수행하는 것이라고 합니다.
수없이 다양한 강아지 사진을 학습하며 그 속에서 스스로 패턴을 찾아내어 나중에는 강아지 사진을 입력하면 고양이와 다른 점을 구분하여 고양이가 아닌 '강아지'라는 정답을 도출해 내는 것입니다.
딥러닝은 머신러닝에 속하는 한 분야로, 인공 신경망(Artificial Neural Network)의 층을 연속적으로 깊게 쌓아올려 데이터를 학습하는 방식을 뜻합니다.
'딥'러닝인 이유도 층을 쌓아올렸기 때문에 깊다는 의미에서 붙은 단어입니다.
딥러닝은 머신러닝의 유형으로 나뉘었던 지도학습, 비지도학습, 강화학습 모두에 이용이 가능합니다.
뉴런이 신경계 속에서 복잡한 구조로 얽혀 거대한 망을 구성하는 것처럼, 머신러닝 과학자들은 이 신경망의 구조에서 착안하여 여러 개의 뉴런이 얽혀서 연결되는 인공 신경망이라는 개념을 만들었습니다.
머신러닝이 학습에 필요한 데이터들을 수동으로 제공해야 하는 것과는 다르게, 딥러닝은 분류에 사용할 데이터를 스스로 학습할 수 있다는 점이 다릅니다. 딥 페이크, 이미지나 영상 복원, LLM, 자율주행 자동차 등 다양한 곳에서 활용될 수 있습니다.
최근 딥러닝은 방대한 양의 데이터로 훈련하며 높은 정확도를 보이고 있기 때문에 사회를 앞으로도 꾸준히 변화시킬 새로운 기술로 큰 주목을 받고 있습니다.
인공 신경망은 날씨부터 주가까지 모든 것을 예측하는 데 있어 점점 더 능숙해지고 있습니다.
결국 머신러닝과 딥러닝 모두 데이터를 기반으로 지식을 학습하고, 이를 바탕으로 예측하는 AI 기술입니다. 하지만 두 기술은 알고리즘과 학습 방식에서 차이가 있습니다.
머신러닝은 전통적인 알고리즘을 사용하여 수동으로 각 데이터의 특징을 알아내고, 다양한 학습 방식으로 이를 진행합니다. 입력 데이터와 출력 데이터 사이의 관계를 학습하는 것에 초점을 맞추는 것입니다.
결국, 데이터를 분석하고 모델을 만들어 미래의 결과를 예측하는 것이 목적입니다. 따라서 수학적 모델을 사용해 데이터를 분석하고, 그 데이터들의 특징을 파악한 후 모델을 만들어 새로운 데이터를 예측하는 게 중요합니다.
반면, 딥러닝은 인공 신경망 기반의 모델을 사용해서 데이터의 특징을 자동으로 알아내고, 학습 방법 중 지도학습을 가장 많이 사용하고 있습니다.
딥러닝은 머신러닝보다 더 복잡한 이미지, 음성, 언어 등 다양한 데이터까지 처리할 수 있기 때문에 더 좋은 성능을 보여주고 있습니다.
